Salesforce's evolving data ecosystem
Salesforce has been evolving its data management and analytics ecosystem at a blistering pace...
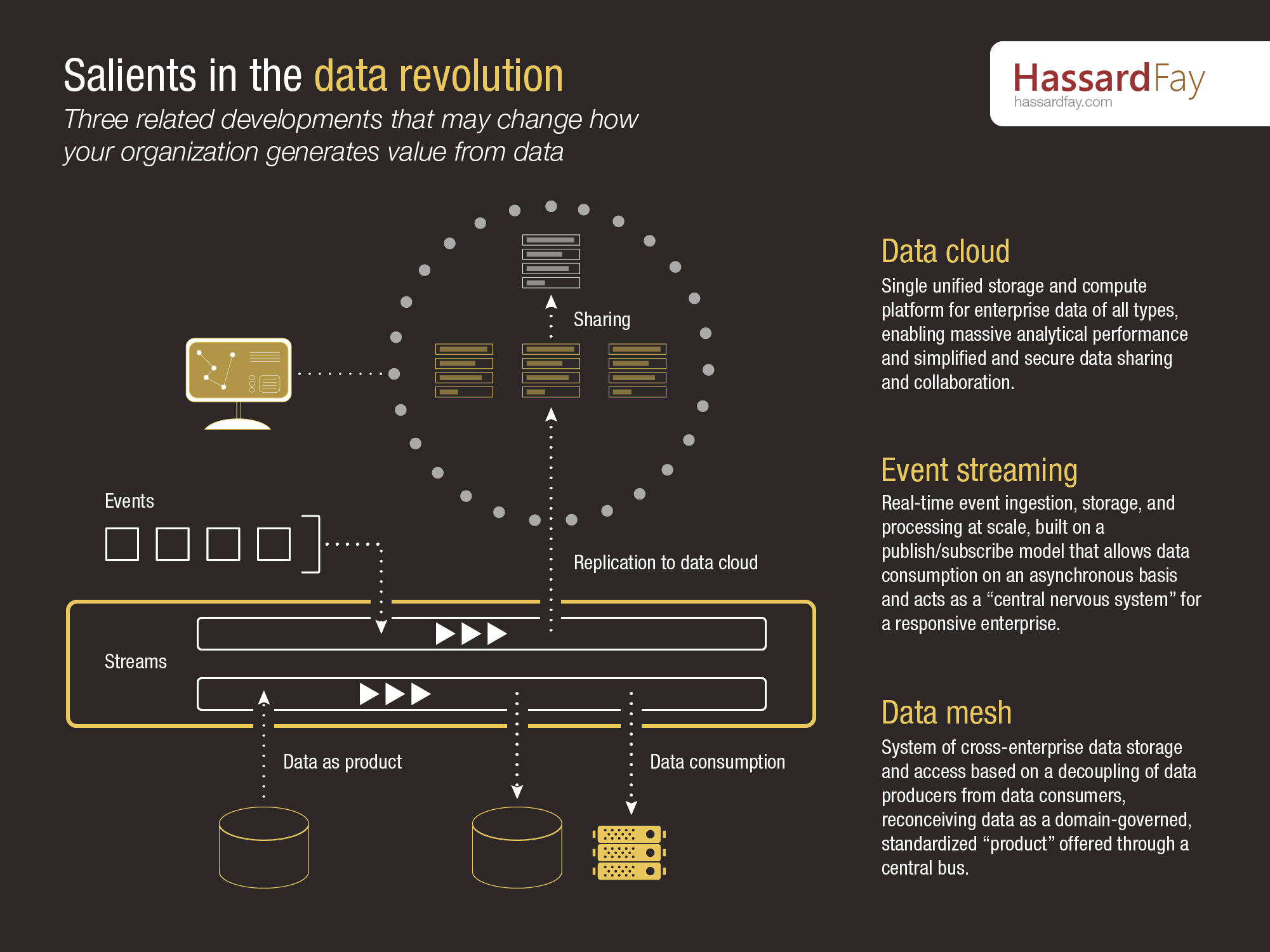
Sometimes the most important revolutions are the quietest. While the value of "data" has certainly been trumpeted from the rooftops over the past twenty years, a more recent series of as-yet-incomplete transformations in how organizations store, marshal, share, and use data have been less-well heralded. And while large organizations (like LinkedIn, in the case of Apache Kafka) have certainly been the driving force behind these innovations, the fact that these approaches are today offered (or can be implemented) as cloud services means that mid-sized and smaller enterprises can take advantage of them to create new services and change how they operate.
Here are three developments to keep a close eye on:
Event streaming & processing
The traditional definition of data is that it's about "facts"—facts that sit quietly until you ask for them—yet the invention of Apache Kafka (and the cloud service version of Kafka offered by Confluent) grew out of a new philosophy that sees data as being about "events" (which, put together, may also comprise facts). Also known as "streaming" or "real-time" data, this approach is most often linked to related technologies like IoT and the mobile web, yet it's about not just speed, but also the on-the-fly processing of data in motion, a capability which enables a level of application responsiveness to new events that makes it comparable to a kind of central nervous system for a business.
Data mesh
Over the past decade, microservices and containerization have broken up the classically "monolithic" application in favour of portability and flexibility, and data may well be on the verge of going through the same process. Though still in an early, mostly conceptual form (read more on it from consulting firm Thoughtworks), the idea of a data mesh envisions the decoupling of data "producers" from data "consumers", turning highly-customized point-to-point extract-transform-load (ETL) pipelines into standardized connections to a central "data bus", and moving much of the responsibility for data quality and transformation to the owners of its respective business domain. In an enterprise data mesh, data is treated as a "product" offered by a domain to all comers, with a published schema and governance processes designed to ensure quality. The goal: an enterprise data architecture that can scale and adapt easily, without the brittleness and cost of today's spaghetti-like networks of pipelines.
Data cloud
Another approach to this goal of unification without complexity is the "data cloud" architecture pioneered with great success by Snowflake. As defined by that company, the data cloud sits on top of public clouds like AWS, Google, and Azure, and offers a single unified space in which to house all of an enterprise's data. Since storage is separated from compute, Snowflake can offer effectively unlimited concurrency and performance for analytical operations, as "virtual warehouse" clusters spin up and scale out in seconds to ensure queries are never slowed by infrastructure limitations. With all customers being nodes in a single cloud, what's more, Snowflake abstracts away the complexities of sharing data with third parties, making inter-enterprise collaboration much simpler and more secure, and opening up a range of new opportunities to monetize or procure data as desired.

Salesforce has been evolving its data management and analytics ecosystem at a blistering pace...

In a fascinating evolution, not only are powerful AI capabilities available in the cloud, but they...
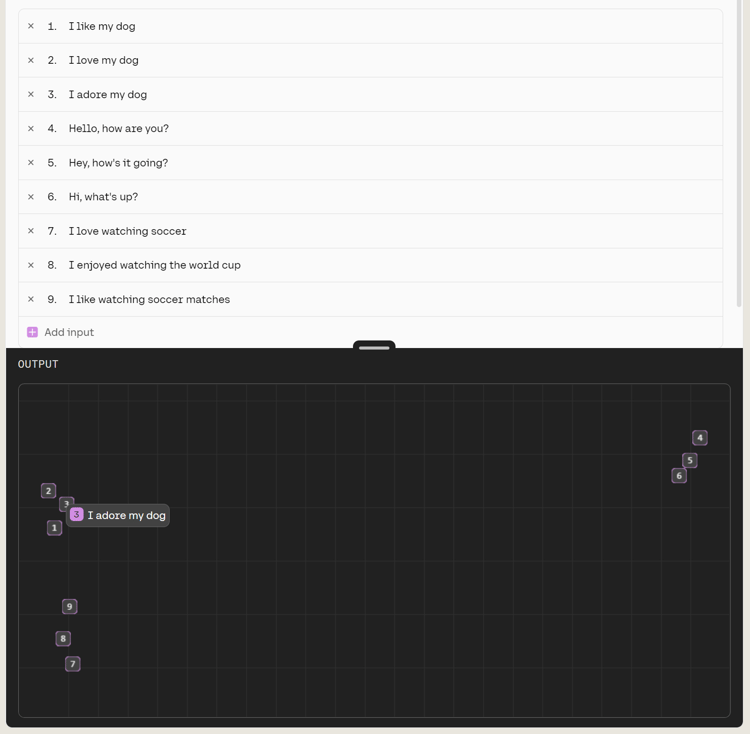
One of the most powerful and fundamental transformations at the heart of how LLMs operate is the...