Embedding language in numbers: how LLMs represent meaning
One of the most powerful and fundamental transformations at the heart of how LLMs operate is the...
Many LLM-based products for the B2C market today focus on answering relatively simple customer questions on the basis of a single source of information (like a FAQ document, or the LLM's training knowledge)—effectively a one-to-one relationship. But what happens in B2B scenarios, where questions are complicated and multi-part, and where the answers are just as complicated and span multiple knowledge sources? How do you use an LLM to handle these "many-to-many" situations?
That's where retrieval augmented generation comes in, which uses orchestration software and LLM-like "vector stores" to allow multi-document information to be indexed, stored, and semantically searched in order to extract the most relevant answers (wherever they may lie) and then send them to an LLM for synthesis and articulation in, for example, an email response to a customer.
I'm building a system like this for a client (using LlamaIndex for orchestration and Chroma as an in-memory vector store), and yesterday I focused on the "question decomposition" problem: how do you take a complicated customer question and break it into sub-questions so that the semantic search function can find answers for each one in turn — rather than getting confused by a single multi-part question and finding only a partially relevant answer?
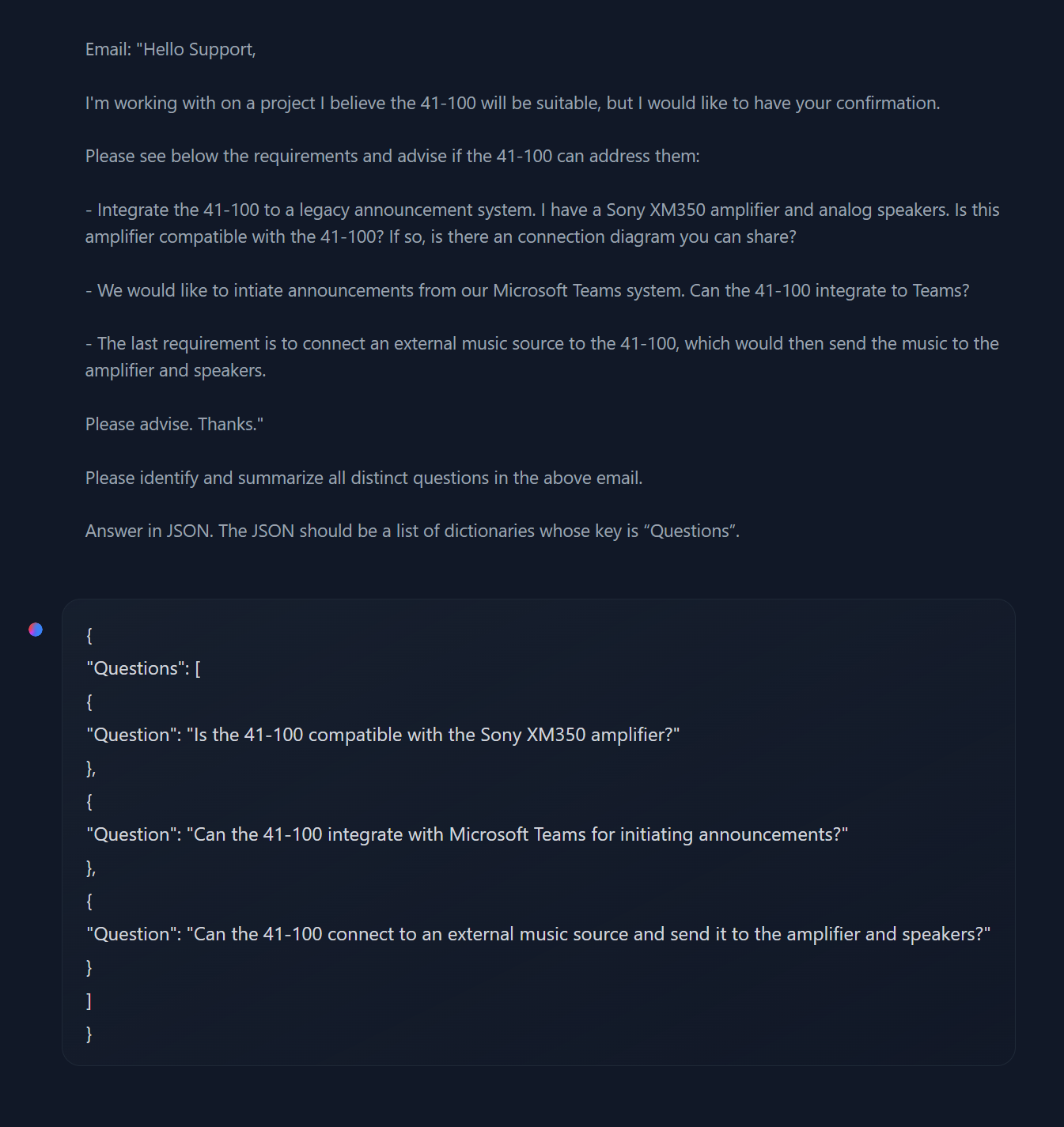
The answer is to use another LLM. I tested a few open source LLMs on this task since the client may want to host one on their infrastructure, and found that Mistral AI's compact 7B model does a good job of question decomposition -- breaking down the question in the screenshot below, for example, into three well-formed JSON dictionary objects ready for parsing -- while still being small enough to serve from an affordable virtual machine.
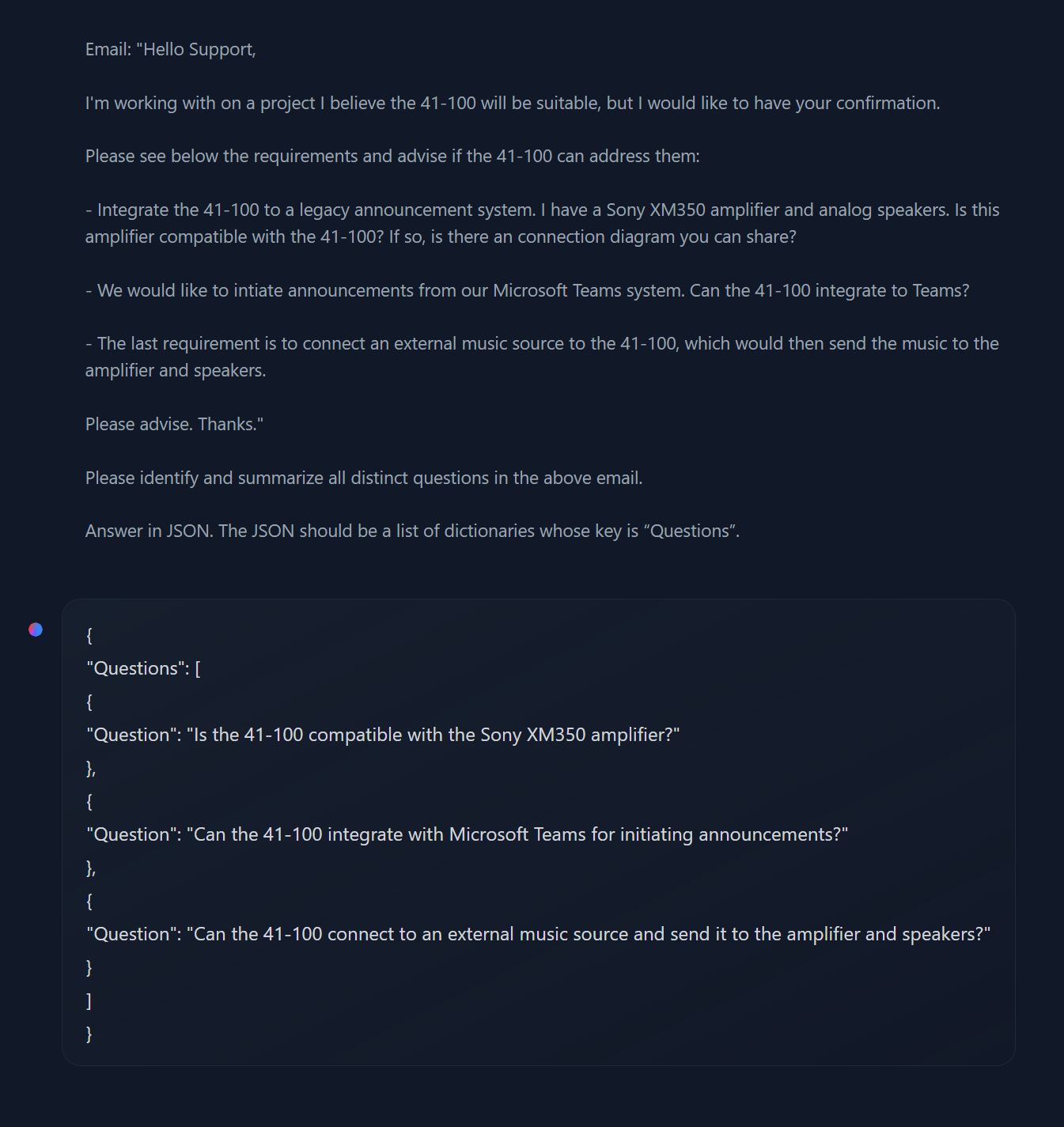
The focused sub-questions it produced, meanwhile, brought back the most relevant answers from the semantic searches, two of them perfectly matching what a human suggested, and one of them coming very close to the human-selected knowledge extract — a huge improvement over the system's performance against the single complicated question.
I'm looking forward to getting this built and seeing it flow end-to-end.
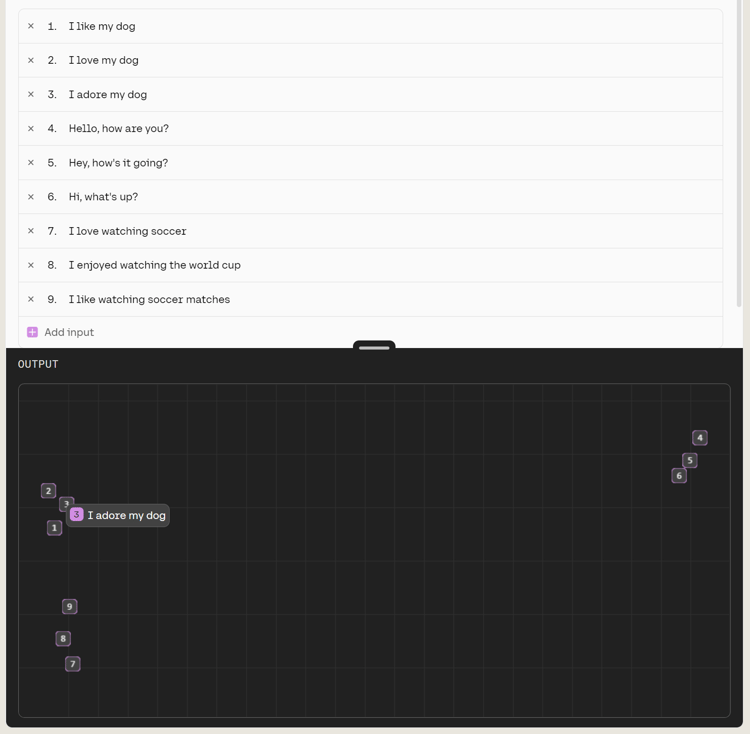
One of the most powerful and fundamental transformations at the heart of how LLMs operate is the...
.png?width=750&name=Screenshot%20(1150).png)
Data visualization has been put to innumerable uses, but depicting how code works is an area less...

Sometimes the most important revolutions are the quietest. While the value of "data" has certainly...